

Predictive Analysis
What is, Where is Used
Predictive analysis is a branch of data analytics that uses current and historical user data to make predictions regarding events. It actually consists of building a model that best fits the specific data characteristics and can predict future events, explain past ones, and group or correlate data records within the dataset
Although predictive analysis and data modelling have been known for a long time, the rise of big data technology and cloud computing, along with low cost data processing, made it viable for almost all organizations. According to recent studies, global predictive analysis market is expected to reach 11 billion USD by 2022, with an average growing of around 21%.
Currently, most companies use predictive analysis in several cross-industry functions and processes such as credit check, fault materials predictions, sales and marketing, delivery optimizations etc.
Marketing departments use predictive analysis methods through automated marketing and sales processes for:
- Predicting user intent
- Personalized content delivery, advertising and after sales support
- Predictive lead scoring
- Account based marketing
- Improved customer engagement
- Higher conversion rates
- Increasing revenue and ROI
Predictive Analysis Process
Predictive analysis process, such as delivering personalized marketing services based on intent data, may consists of several sub-processes:
.png?width=600&name=image%201%20(3).png)
Data Retrieval
Input data, i.e. user intent data in the specific example, may come from multiple sources for predictive analysis. They may be:
- 1st party data - internal data- that can be retrieved from owned data sources such as a CRM or company’s website or social media. Usually these are structured and unstructured data, but valuable for the analysis
- 3rd party data - external data- that are bought from data providers. In some cases data may not be retrievable at customer level and segmentation should be applied (e.g. anonymous customers or visitors).
Since raw data comes from different data sources, they should be consolidated and transformed after extraction to be usable.
Data Analysis, Statistical Analysis, Data Cleansing
Data analysis and cleansing consist of discovering possible anomalies such as missing information or noise, consolidating and validating the data, and then storing it in a data warehouse. Depending on the model and required segmentation, patterns may be applied to discover similarities
Predictive Model
Depending on the outcome requested, previously performed statistical analysis, and the discovered patterns for a specific dataset, you can apply a prediction model to achieve the best prediction for the probability of an outcome. However it is important to note that the accuracy and usability of the results will depend greatly on the level of data analysis and the quality of your assumptions.
The predictive model lifecycle consists of the following sub-processes :
.png?width=600&name=image%202%20(3).png)
Along with deploying and running the model, you should run a process monitor in parallel to gain improvements. This lets you continuously evaluate the model for possible adjustments:
- Either the model parameters and initial assumptions need fine tuning
- Or the initial dataset was expanded with new data, such as sales transactions or social media postings
Predictive Model Types
Predictive models are machine learning methods that may either produce a prediction or imply a prediction based on a score, or find patterns and potential data groupings and segmentations. These models come in two main categories:
- Supervised models: where input, the independent variable, is statistically modelled and generates a prediction based or implied though an outcome, the dependent variable. Input data may be separated to data used to build the model (training data) and data used to evaluate the model (evaluation data)
- Unsupervised models: where input is statistically modelled in order to find patterns and similarities, group data and find exceptions without having an outcome. Unsupervised machine learning is the most common category
.png?width=600&name=image%203%20(4).png)
Regression Models
Statistical regression models use regression analysis methods to find relationships between the values of one or more independent variables (the input) with one dependent variable (the output). Based on the relationships discovered, someone can predict the output for any other new input.
Common regression model types include
- Linear regression: the relationship between the input and output is linear. These are the simple linear (single input variable) and multi linear regression (multiple input variables)
- Polynomial regression: - the relationship between input and output is non-linear (e.g. polynomial)
- Logistic regression: - output is of Boolean type (0/1 or True/False values). Interception of logistic regression models may form a neural networks model.
.png?width=600&name=image%204%20(3).png)
Classification Models
Classification models are identical to regression ones, but the dependent variables are discrete values instead of continuous .
Classification model types include:
- Naive Bayes: output value depends on input variables weighted by a probability factor. Interceptions of Naive Bayes may also form neural networks.
- Decision trees: classifications are predicted through a decision tree consisting of nodes and leafs.
- Random forests: similar to decision trees but including some randomness in order to push out bias and group outcomes, based upon the most likely positive responses.
.png?width=600&name=image%205%20(3).png)
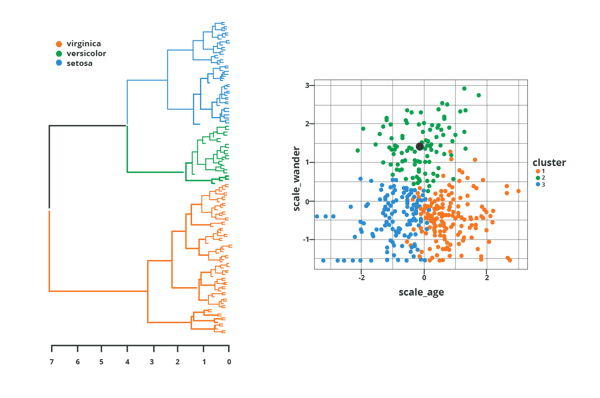
Clustering Models
Clustering models find similarities between data based on common attributes and then group them into clusters.
Clustering models include:
- K means - nearest neighbor, where k number of clusters (aggregations) are formed based on the minimum distance between training data.
- Hierarchical clustering - two most similar clusters are combined to form a single one. After several iterations this leads to a single or few clusters.
Challenges When Deploying a Predictive Analysis Model
Implementing a predictive analysis model is often a difficult project, requiring detailed design and specifications, continuous commitment, and strong governance. It involves several functions within an organization including information technology, marketing and sales, and others. Except for the common challenges that come with any project, predictive model deployment challenges are related mainly to data and the model.
Data-Related Challenges
User data for predicting intent can come from various data sources:
- Voluminous structured data coming from the backend systems with detailed attributes and features.
- Unstructured data coming from social media. This complexity can create certain challenges while deploying a predictive model. To overcome them, the predictive analysis process should assure the quality and quantity of the training data.
Data Quality / Cleansing
While uploading the above data to a data warehouse database, errors such as inconsistent data, duplicates, logic conflicts, and missing data may appear. Data consolidation should remove the noise.
Over-Cleansed Data
On the other hand, if there are strict rules , and the data gets over-cleansed, then the data does not correspond to real data, making training data inaccurate and the prediction model unreliable.
Old Data are Out of Date
Often, user master data, such as customers, appear several times in backend systems. They may be distinct entities that point to the same customer. Old data should be marked as old and kept out of scope since training a model with old data may lead to wrong conclusions regarding predictions.
Not Enough Data
Among other factors, model reliability depends strongly on the training dataset size. Following this rule, a large training dataset is more reliable than a smaller one. This is a fundamental machine learning challenge called cold start, where the model is not effective in the beginning due to the lack of data. You can find this in cases of a new product, a new customer group, etc.
Too Much Data
From a statistical point of view, beyond a point, feeding the model with data does not improve the accuracy of predictions. This may waste computational and time resources.
Underestimate Social Media Data
Social media contains valuable information regarding behavior and attitude that are often more valuable than attributes hidden in transactional data. But intent data coming from social media are unstructured and difficult to interpret.
Overestimate Surveys
Often, predictive models rely on intent data coming from surveys or submitted forms. But surveys completion rate is low and usually customers that submit such information are the loyal ones. This may lead to non-representative training data and a non-reliable prediction model.
Anonymous Customer
Predicting the outcome of anonymous customer remains a challenge, since you do not have a lot of information about this type of customer. Usually, it is restricted to geographic location data and site browsing history. A lot of effort has gone in building unsupervised techniques for predicting what a customer group will like but it still remains a big challenge.
Model Related Challenges
Model type selection, along with input features -independent variables- selection, is critical in building a predictive model.
Model Complexity
To cover a wider range, models may incorporate many input variables creating a complex and expensive model. These models are difficult to monitor and adjust, making them an inefficient way to predict outcomes. Instead of quantity, you should focus on the accurate selection of the input variables .This requires a deep understanding of clinical domain knowledge, the business objectives at hand, and the data on which the model will be run.
Wrong Algorithm Selected - Simplified Model
There is a trend, and a principle, that the best solution is the simplest one. Simple linear models are easy to understand and build, require less computational resources, and they can be easily adjusted. But reality often is not linear.
Wrong Features Selected
Primarily due to a lack of knowledge, the model input may include wrong data features (input variables) or features that contain much noise, lowering the prediction efficiency.
Model Evaluation
While, evaluation methods and metric are clear in supervised machine learning, this is not the case in unsupervised models where metrics may not reflect the model outcome. For example, a good F1 score may have value only if the evaluation data cover all desired features in the model.
Conclusion
Predictive analytics opened up a new realm of possibilities in many areas within an organization. But since they are reliant on set models and data solutions, they can present problems with deployment and thus not being efficient if they are not optimized.


Leave a Comment